Analiza metadanych plików PDF w Polsce
1. Wyniki
- Znaleziono i przeszukano 887 472 stron internetowych w domenie .pl
- Pobrano i przetworzono 1 452 074 plików PDF(łącznie z plikami w domenie innej niż .pl)
- Łączny rozmiar pobranych plików PDF wyniósł 1 334 gigabajty
Z zebranych metadanych powstały, w formie wykresów, następujące raporty:
- Liczba wygenerowanych plików PDF według producenta oprogramowania
- Liczba wygenerowanych plików PDF według twórcy oprogramowania(programu generującego)
- Liczba dokumentów z podziałem na wersję PDF
- Liczba dokumentów PDF z podziałem na ilość stron
Na wykresach uwzględniono producenta/twórcę dla liczby dokumentów powyżej 5 tysięcy.
Przejdź do wykresów
2. Sprzęt
Ze względu na ograniczone zasoby sprzętowe oraz brak chęci ponoszenia dodatkowych kosztów proces skanowania przeprowadzono na posiadanym sprzęcie - 1 serwer z łączem 70Mbps(download) oraz przeznaczoną do celów skanowania Internetu maszyną wirtualną wyposażoną w 5GB pamięci RAM. Cały proces gromadzenia nowych domen oraz linków do plików PDF został wykonany za pomocą tejże maszyny wirtualnej.
3. Oprogramowanie
Jako pająk sieciowy wykorzystany został ogólnodostępmy framework napisany w języku Python.
4. Przebieg
Proces gromadzenia danych polegał na uruchomieniu ok. 150(a w fazie końcowej 250) instancji pająka. Każda instancja skanowala jedną domenę. W początkowej fazie wyszukiwane były nowe domeny i pliki PDF, które pobierano i analizowano na bieżąco. Szybko okazało się, że zasoby pamięci i procesora nie są wystarczające, konieczne było zmniejszenie liczby instancji co wiązało się ze znacznym wydłużeniem trwania projektu. W związku z powyższym pająk otrzymał za zadanie wyłącznie wyszukiwanie nowych domen, linków PDF oraz dodawanie ich do bazy danych w celu dalszego przetwarzania.
Ze względu na działające inne projekty, zdecydowano aby pobieranie plików PDF oddelegować poza serwer główny. W tym celu wykorzystano darmowe instancje OpenShift. W celu komunikacji klientów zewnętrznych z bazą danych powstał webservice, który umożliwia pobranie adresu URL do przetworzenia oraz zwrócenie wyników. Webservice wykorzystywany jest również w etapie III projektu.
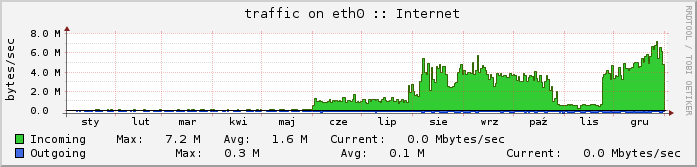
5. Czas
Skanowanie trwało od 1 czerwca 2014r. do 23 listopada 2014r. W sierpniu 2014 rozpoczęto realizację etapu II - na wykresie widać znaczny wzrost użycia łącza. Proces jednak przerwano pod koniec października 2014 w celu szybszego zakończenia etapu I.