Analysis of PDF files metadata in Poland
1. The results
- Found and searched 887 472 websites in the domain .pl
- Collected and processed 1 452 074 PDF files (including files in a domain other than .pl )
- The total size of downloaded PDF files is 1 334 gigabytes
The following reports were created in the form of charts:
- Number of generated PDF files according to producer's software
- Number of generated PDF files by creator (generating program)
- The number of PDF documents based on specification version
- The number of PDF documents with a breakdown of the number of pages
The graphs present information for producer/creator where the number of files is above 5 000.
Go to the charts
2. Hardware
Due to the limited hardware resources and a lack of willingness to incur additional costs,
the scan was performed on owned equipment - 1 server with a link 70Mbps (download)
and dedicated
for scanning the Internet virtual machine equipped with 5GB of RAM. The whole process of collecting
new domains and links to PDF files has been made with this particular virtual machine.
3. Software
Open Source framework written in Python.
4. Progress of the project
The data collection process was to run approx. 150 (in the final stage 250) instance of spider. Each spider processed a single domain. In the initial phase, spider searched for new domains and PDF files, which were collected and analyzed on an ongoing basis. It quickly turned out that memory and CPU resources are not sufficient. It was necessary to reduce the number of instances, which led to a significant prolongation of the project. Accordingly, the spider only received the task of finding new domains, PDF links, and add them to the database for further processing.
Due to other active projects, it was decided to delegate downloading of the PDF files outside the main server. To complete this task free instances of OpenShift project were used. A webservice was written to allow clients sending and downloading data from database. The Webservice is also used in stage III of the project.
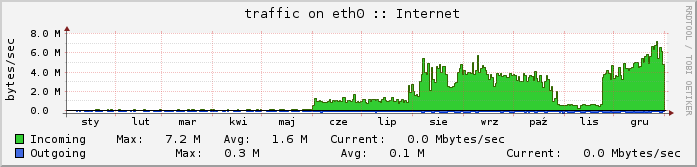
5. Duration of the project
Scanning lasted from 1 June 2014 to 23 November 2014. In August 2014 Phase II was launched - on the chart you can notice a significant increase in the use of the link. However, the process was stopped at the end of October 2014 in order to accelerate the completion of phase I.